Cuando empezamos a hacer el recorrido por los resultados de Gödel ya teníamos en perspectiva cómo eventualmente llegaríamos a enlazarlos con la noción de no-computabilidad. De hecho, esta noción emana de manera natural de los teoremas de incompletitud, y viceversa: partiendo de la noción de no-computabilidad llegamos a la conclusión de que la consistencia y la completitud de un sistema formal lo suficientemente complejo son características incompatibles entre sí. Vamos a ver por qué sucede esto, y para ello es necesario partir de una definición de computabilidad que nos permita entender qué quiere decir no-computable.
Intuitivamente y sin entrar en muchos detalles, la noción de computabilidad en relación a un cierto problema hace referencia a la posibilidad de disponer de un algoritmo para resolverlo, esto es, que exista un procedimiento mecánico, con descripción finita y no ambigua, y que resuelva dicho problema en tiempo finito. Esto enlaza claramente con el programa formalista de Hilbert, en el que se pretendía tener un procedimiento de este tipo para demostrar/refutar cualquier afirmación matemática expresada en ese hipotético sistema formal definitivo que se anhelaba. En este contexto, el que Gödel hubiera demostrado en su denominado Teorema de Completitud que toda afirmación universalmente válida en la lógica de primer orden es demostrable, conducía a la cuestión obvia de encontrar esa demostración (o determinar su inexistencia) para una cierta expresión lógica. Si nos fijamos un poco, es fácil ver que esta cuestión en el fondo se reduce a determinar si existe una demostración o no, ya que una vez se ha determinado que existe, basta generar sistemáticamente todas las demostraciones (por ejemplo, ordenadas crecientemente por su número de Gödel) hasta dar con la demostración que nos interesa. La determinación de la existencia de una demostración para una fórmula arbitraria de la lógica de primer orden es lo que se conoce como problema de la decisión (Entscheidungsproblem en alemán).
¿Existe algún procedimiento mecánico (un algoritmo) para resolver el problema de la decisión? La respuesta es «no». Para ver por qué partamos de algún tipo de formalismo para expresar algoritmos, por ejemplo una máquina de Turing (MT). Los detalles del formalismo son realmente poco importantes aquí, pero sí es interesante el hecho de que una MT captura bien la idea intuitiva de procedimiento secuencial, en el que se van realizando acciones paso a paso, y se van tomando decisiones sobre qué acciones realizar. En el marco de un procedimiento de este tipo es natural preguntarse sobre si acaba eventualmente o no. Para formalizar un poco esta idea, consideremos en primer lugar que una MT es una descripción finita de un procedimiento, por lo que podemos codificar dicha descripción como un número natural, de manera similar al proceso de gödelización. Así, Mn es la MT cuya codificación es el número n. Del mismo modo, si el procedimiento admite unos datos de entrada, éstos serán también finitos y representables mediante otro número natural. Diremos entonces que Mn(m) -donde m,n son números naturales- es el resultado de aplicar Mn a los datos de entrada representados por m. En caso de que Mn(m) no se detuviera, diremos que Mn(m)=■.
Vamos a plantearnos ahora la cuestión de si una MT particular se para con unos ciertos datos de entrada o no. Supongamos que se trata de una cuestión computable, esto es, que existe una MT H que tomando como entradas m y n determina si Mn(m) se para o no. Por ejemplo,

Es fácil demostrar que esta MT no existe haciendo uso del corte diagonal. Para ello, definamos F(n) = 1 + H(n,n) · Mn(n), es decir,
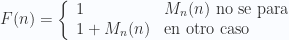
Si H existe, no hay dificultad en definir una MT como F, cuya codificación será un cierto valor r (es decir, Mr=F). Ahora, ¿se detiene F(r)?
- Si la respuesta es afirmativa, entonces H(r,r) = 1, con lo que F(r) = 1+F(r), lo que es una contradicción.
- Si la respuesta es negativa, entonces H(r,r) = 0, con lo que F(r) = 1, lo que no tiene sentido, ya que F(r)=■.
Llegamos a una contradicción en ambos casos, por lo que la suposición de partida -que existe H– es falsa. La única posibilidad que tendríamos de escapar de la contradicción es pensar que H es sólo un resolutor parcial de parada (PHS, por sus siglas en inglés), es decir, que puede determinar correctamente si algunos procedimientos se paran o no, pero a veces el propio H no llega a pararse. En otras palabras, H daría una respuesta correcta, o no daría respuesta. En ese caso, no hay inconveniente en suponer que F(r) no se para (i.e., H(r,r) = ■, F(r) = ■). El problema es que no tenemos forma de determinar en general si H es un PHS fiable. Si lo pudiéramos determinar, esto es, si existiera un procedimiento R tal que

entonces podríamos definir un procedimiento XN

donde N es una cierta constante. La codificación de XN sería w, o más precisamente w(N), dependiendo del valor de N. Definamos ahora un procedimiento Q(n)=R(w(n)). Este procedimiento devolverá 1 si, y sólo si, Xn está en lo cierto al decir que Mn se para (asumimos sin pérdida de generalidad procedimientos sin datos de entrada), es decir, tendríamos un resolutor completo de parada. Como esto es imposible, no podemos disponer por lo tanto de un reconocedor de resolutores parciales de parada.
Hemos encontrado un problema al que no podemos dar respuesta computacionalmente. Las implicaciones de este hecho son enormes. Podemos por ejemplo desandar un poco el camino, y ver que la cuestión de la detención de una cierta MT es expresable mediante una fórmula lógica de primer orden. El que se trate de un problema no computable implica que dicha fórmula es indemostrable e irrefutable, lo que nos lleva a dar una respuesta negativa al problema de la decisión, y enlazar con el primer Teorema de Incompletitud de Gödel. Con todo y con ello, lo más interesante es la cantidad de problemas aparentemente simples que por mor de la no-computabilidad del problema de la parada resultan ser no-computables también. Otro día veremos algunos de ellos.




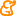
























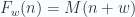



![{\rm Cons}(S) \Rightarrow \left[\sim\exists x D(x,g(G))\right]\wedge \left[\sim\exists x D(x,g(\sim G))\right]](https://s0.wp.com/latex.php?latex=%7B%5Crm+Cons%7D%28S%29+%5CRightarrow+%5Cleft%5B%5Csim%5Cexists+x+D%28x%2Cg%28G%29%29%5Cright%5D%5Cwedge+%5Cleft%5B%5Csim%5Cexists+x+D%28x%2Cg%28%5Csim+G%29%29%5Cright%5D&bg=fafcff&fg=2a2a2a&s=0&c=20201002)
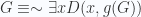


 ,
,