

















La combinatoria de los brotes epidémicos
Posted by Carlos en agosto 28, 2007
Uno de los aspectos claves para lidiar con brotes epidémicos es la identificación de los mismos (luego viene algo mucho más complejo que es analizar su dinámica para localizar el origen/causa, y predecir su evolución, pero dejemos eso para otra ocasión). Esta identificación no es algo trivial. Indudablemente, si se detectan cientos de casos de una enfermedad muy rara en un área muy reducida se está ante un fenómeno epidémico, pero el objetivo es realizar la identificación en una etapa más temprana, antes de que la enfermedad se disemine sin control. La clave está entonces en realizar una evaluación de cuándo un cierto número de casos de una enfermedad puede estar siendo motivada por un brote epidémico. Esto lógicamente dependerá de diferentes factores, como el número de casos, la prevalencia de la enfermedad, o el tamaño de la comunidad en la que se han detectado los casos. La combinatoria nos puede echar una mano en este caso. Concretamente, el clásico modelo de bolas y cajas puede ser muy útil. Veamos cómo.
Supongamos que tenemos un número N de cajas, sobre las que distribuimos uniformemente al azar B bolas. Cada una de estas cajas representará lógicamente un grupo o comunidad, y cada bola será un caso de la enfermedad en cuestión. La pregunta que queremos hacernos es si el hecho de que hayan caído m bolas en una cierta caja representa un evento estadísticamente improbable y por lo tanto existe una probabilidad no desdeñable de que haya una causa para el mismo más allá del azar. ¿Cuál es la probabilidad de una cierta configuración de bolas en las cajas? Dicha probabilidad viene determinada por la bien conocida distribución multinomial:

donde pi es la probabilidad del evento i, xi es el número total de veces que se produce dicho evento, y x=x1+…+xk. En nuestro caso suponemos N eventos distintos (elegir una caja concreta), pi=1/N (todas las cajas tienen la misma probabilidad), y si bi es el número de bolas en la caja i, b1+…bN=B. Entonces,

La probabilidad de que el número de bolas en la caja que más tiene sea menor o igual a m es
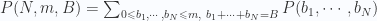
Finalmente, la probabilidad de que haya m o más bolas en la caja que más tiene es 1-P(N,m-1,B). El problema que tiene calcular de manera precisa esta expresión es la explosión combinatoria para valores grandes de N y B, motivo por el cual se emplean aproximaciones (por ejemplo basadas en métodos de Monte Carlo). Al menos esto era hasta ahora, ya que Warren J. Ewens, y Herbert S. Wilf, de la Universidad de Pennsylvania, han encontrado una forma eficiente de realizar el cómputo, según describen en un artículo titulado
publicado en los Proceedings of the National Academy of Sciences. El método de Ewens y Wilf se basa en el hecho de que P(N,m,B) es B!/NB veces el coeficiente de xB en la serie em(x)N, donde em(x) es la expansión polinómica de la función ex truncada en el término (m+1)-ésimo, y que estos coeficientes se pueden calcular eficientemente mediante una relación recurrente. De hecho su algoritmo emplea una cantidad de memoria O(m), y tiene un coste computacional O(mN).
Ewens y Wolf ilustran el método con dos ejemplos. En el primero se analiza la aparición de 8 casos de leucemia infantil en un pueblo de 20,000 personas. Durante el periodo en el que surgieron estos casos el número medio en todo el país (EE.UU.) era de 1.6 por 20,000 habitantes, y la población total era por aquel entonces de 180 millones. El análisis se realiza entonces con N=9,000 (180,000,000/20,000), B=14,400 (1.6·9,000), y m=8, resultando en una probabilidad del 90%, lo que no apoya la hipótesis de una causa común para estos casos. En el segundo ejemplo se analizan 12 casos de leucemia linfocítica aguda en un pueblo de 24,000 personas, cuando el número esperado era de 1, y la población total del país es de 288 millones. Tenemos entonces N=12,000, B=12,000, y m=12. En este caso la probabilidad de que todo sea debido al azar es virtualmente cero (ya para m=8 es sólo del 0.6%), por lo que la hipótesis de la causa común no puede ser obviada.
Por supuesto, en ambos casos se trata sólo de una estimación estadística, pero puede ser de gran utilidad para activar los sistemas de alerta, máxime teniendo en cuenta que el cómputo puede realizarse en sólo unos segundos en un ordenador portátil.
Una respuesta to “La combinatoria de los brotes epidémicos”
Sorry, the comment form is closed at this time.

benjamín said
Necesito entender lo que es FUNDAMENTOS Y MODELOS DE LA DINÁMICA DE SISTMAS EN EPIDEMIOLOGÍA. También lo que es el Modelado de un brote epidémico mediante dinámica de sistemas y un ejemplo de esto con la malaria.